
Alexander Schwing
Associate ProfessorDepartment of Electrical and Computer Engineering
Department of Computer Science
Coordinated Science Laboratory
University of Illinois at Urbana-Champaign
Office: CSL 103
eMail:
@alexschwing

Delineating (i.e., segmenting) objects as a whole (i.e., amodal segmentation) is a challenging task. How can we see the unseen, i.e., how can we segment occluded parts? We think this is only possible if algorithms understand objects as a whole rather than algorithms assessing whether a pixel belongs to an object. Moreover, we think temporal information, i.e., understanding how objects move, is important. However, there was no dataset which delineates objects as a whole for every frame of a video. To facilitate this we collected the 'semantic a-modal instance level video object segmentation' (SAILVOS) dataset.
We hope this dataset will enable new research in the direction of amodal instance-level segmentation. Please feel free to reach out with questions and suggestions.
Check out our website for more.

Training generative adversarial nets (GANs) used to be challenging. In a sequence of papers we studied the reasons. Specifically, in 'Dualing GANs' we used the mathematical concept of duality to reformulate the original GAN min-max objective (saddle point) into a minimization. This yielded exciting relations between GANs and moment matching but wasn't easy to scale.
Subsequently, we showed in 'Sliced Wasserstein GAN' that duality (Kantorovich-Rubinstein) can be removed from the Wasserstein GAN objective by using projections onto many one-dimensional spaces. To reduce the number of one-dimensional spaces we subsequently introduced the 'Max-Sliced Distance' which we found to be very easy to train.
In our research on image inpainting we found back-propagation through GANs to the latent space to be challenging . We studied the reasons in our work on 'annealed importance sampling with Hamilton Monte Carlo for GANs' .
Check out some of our code for more: Sliced Wasserstein GAN, Backpropagation

In collaboration with AI2 we develop algorithms and environments for collaborative and visual multi-agent reinforcement learning. It seems implausible to develop a single agent which can address all tasks on its own. Adressing tasks in collaboration seems much more feasible. Yet understanding collaborative visual reinforcement learning with communication is at its infancy. We are interested in changing this.
In our recent 'Two Body Problem' work we showed that communicative agents can solve a challenging task much faster.

We recently started to develop algorithms which can anticipate what the current observation will look like a few seconds from now. Following the vision of neuroscientist Kenneth Craik we agree that 'a creature must anticipate the outcome of a movement to navigate safely' (1943). In a first project on 'Diverse Generation for multi-agent sports games' we looked at team-sports data and showed how to anticipate future movement of players and how to answer counterfactual questions related to what would have happened if the ball trajectory was modified.
In subsequent work on 'Chirality Nets' we studied human pose forecasting with structured representations.
Check out our website for more.
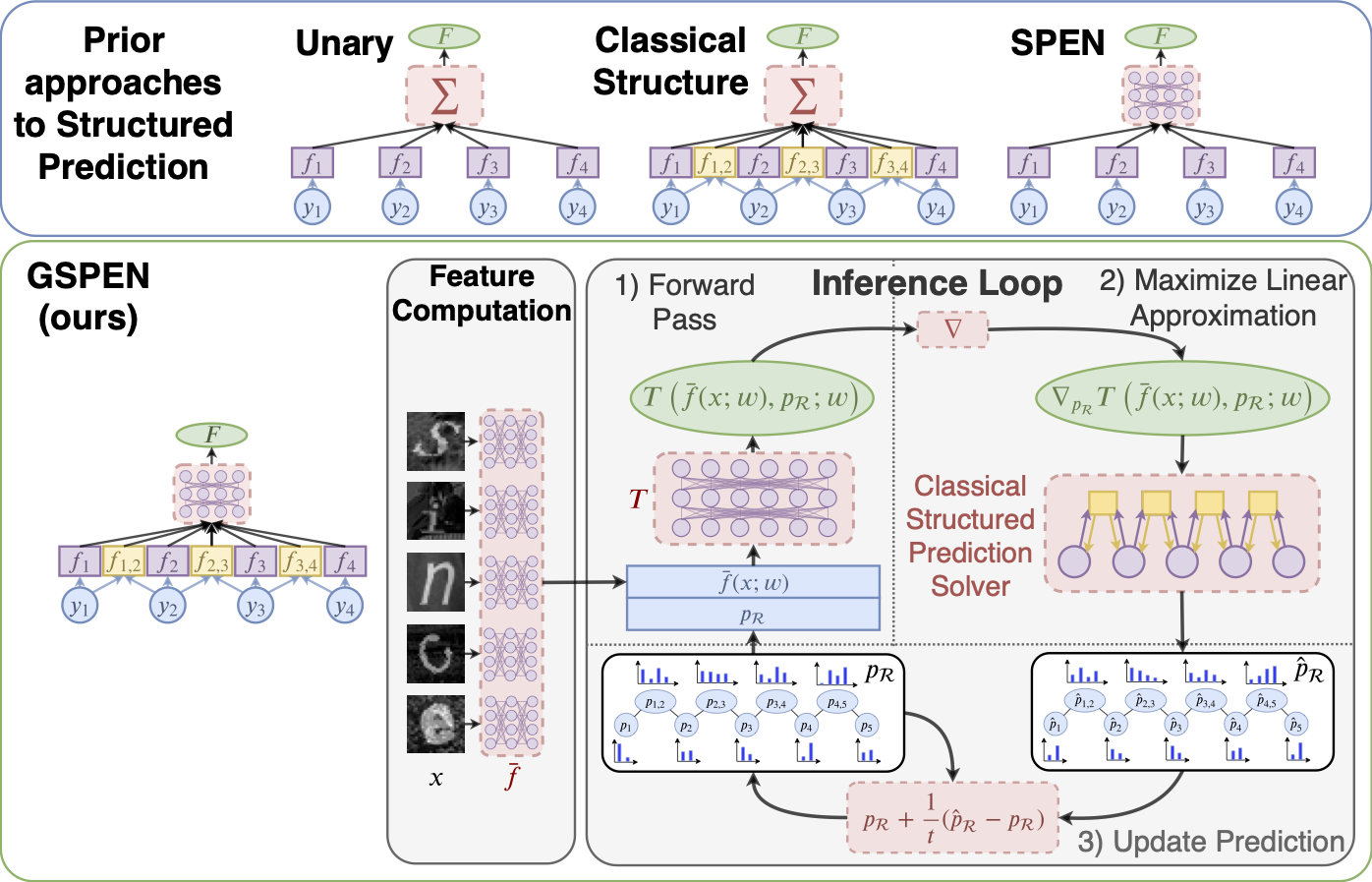
Structured prediction is an area that I have worked on for many years, already during my PhD and PostDoc. For instance, jointly with my advisors and collaborators we developed deep structured models , algorithms for globally convergent maximum a-posteriori (MAP) inference , asynchronous MAP inference , and distributed MAP inference . We continue to develop more efficient algorithms for inference in structured models and more expressive models. For example, in recent work we introduced 'NLStruct' which is able to capture non-linear correlations. A shortcoming of 'NLStruct' is its saddlepoint objective which makes it challenging to optimize. Therefore, more recently we developed 'GSPEN' which is more expressive and easier to optimize.
Check out our code for more.

We are interested in developing algorithms for weakly-supervised and unsupervised video object segmentation. Given segmentation annotations for the first frame, classical methods require an expensive finetuning step. This limits scalability of those methods. We address this concern in 'VideoMatch' . Specifically, instead of a classification problem we propose to formulate the task of instance level video segmentation as a matching. Consequently, finetuning is no longer require to obtain good results. In addition, in our 'MaskRNN' work we exploit temporal correlations for accurate instance level video object segmentation. We also study unsupervised video object segmentation .
Describing an image is an important task. Classical methods only provide a single description for an image. We argue that this does not live up the standard: we want to provide many equally suitable descriptions. In other words, we aim to better capture the ambiguity in vision-language tasks. In this direction we first looked at 'Creativity' using generative models (variational auto-encoders). To include controlability we then extended this to conditional models and also studied its ability to form a meaningful dialog . We later found in 'ConvCap' that convolutional models are not as overly confident as classical long-short-term-memory based techniques, which helps to better capture ambiguity. Moreover, convolutional models can be conditional as well . More recently, we studied how language models can anticipate/forecast how a sentence will be completed by using more fine-grained latent spaces . We found this technique to significantly boost the ability to better capture ambiguity.
We also study diversity aspects for visual question answering via attention models and factual visual question answering. For the latter we developed techniques to include information from knowledge basis either directly into prediction or via graph neural nets .
We also developed optimization techniques for supervised visual grounding and its unsupervised counterpart .
Check out some of our code for more: Convolutional Captioning

We are interested in developing efficient practical multi-agent reinforecement learning algorithms. Classical techniques use a critic which has to learn from data that an environment should be assessed identically if the agents are permuted. This makes multi-agent reinforcement learning even more sample inefficient. To address this concern we recently introduced the permutation invariant critic (PIC) . As the name suggests, PIC guarantees that an environment is assessed identically, irrespective of the agent permutation. We found this to significantly improve scalability.
Check out our code to train systems with up to 200 agents: Permutation Invariant Critics












